Śpiewajcież aniołowie
 Nadchodzi czas śpiewania kolęd. Co prawda nie znam nikogo, kto by to robił chętnie i bez zażenowania. No dobra, pewnie znam, ale wyparłem to ze świadomości. Ja w każdym razie raczej śpiewał nie będę.
Nadchodzi czas śpiewania kolęd. Co prawda nie znam nikogo, kto by to robił chętnie i bez zażenowania. No dobra, pewnie znam, ale wyparłem to ze świadomości. Ja w każdym razie raczej śpiewał nie będę.
Jak powstaje śpiew? W zasadzie tak samo jak mowa. Ludzkie drogi oddechowe są rurą, w której powstaje fala akustyczna. Różnego rodzaju mruki, mlaski i cmoki powstają przez przepychanie powietrza przez różne bariery w tych drogach, ale większość tego, co określamy jako dźwięki, powstaje dzięki drganiom strun głosowych w krtani.
Otóż wcale nie strun – to, co drga w krtani, to nie żadne naprężone włókna wiszące w poprzek światła przewodu oddechowego. Tak naprawdę są to fałdy głosowe. Między fałdami głosowymi znajduje się szpara głośni, a w krtani poza głośnią (obejmującą fałdy głosowe i szparę) znajdują się też inne fałdy, niebiorące bezpośrednio udziału w tworzeniu głosu, ale izolujące przewód oddechowy.
Fałdy głosowe zresztą też to robią i wydaje się, że to jest ich pierwotna funkcja, natomiast ich istnienie u naszych przodków stało się ewolucyjną preadaptacją (egzaptacją) umożliwiającą wydawanie głosu. Krtań przechodzi w gardło, którego jama w zasadzie bez wyraźnej granicy przechodzi w jamę ustną, a przegrodą między tymi dwiema jamami a jamą nosową jest podniebienie – twarde (nieruchome) i miękkie (ruchome). Na końcu tego układu są usta i nozdrza.
Na końcu, patrząc z perspektywy płuc, które wypychając powietrze na zewnątrz, nadają dynamikę całemu procesowi. To wypchnięte (chwilowo zapomnijmy o głoskach ingresywnych) powietrze wpada między fałdy. Fałdy głosowe są oscylatorem powstających zagęszczeń powietrza, a więc fali, a cały przewód głosowy, od krtani po usta, jest rezonatorem.
Powietrze, napierając na zwarte fałdy, rozwiera je, one z powrotem się zwierają i tak dalej. Częstotliwość tych drgań decyduje o częstotliwości drgań powietrza, a więc ostatecznie o częstotliwości fali akustycznej. Fal powstaje mnóstwo. Ta, która powstaje bezpośrednio dzięki drganiom fałdów głosowych, ma częstotliwość podstawową, czyli ton podstawowy. Oprócz niej powstają tony dodatkowe. Te, których częstotliwości są odpowiednim zwielokrotnieniem tonu podstawowego, rezonują i stają się bardziej słyszalne niż reszta.
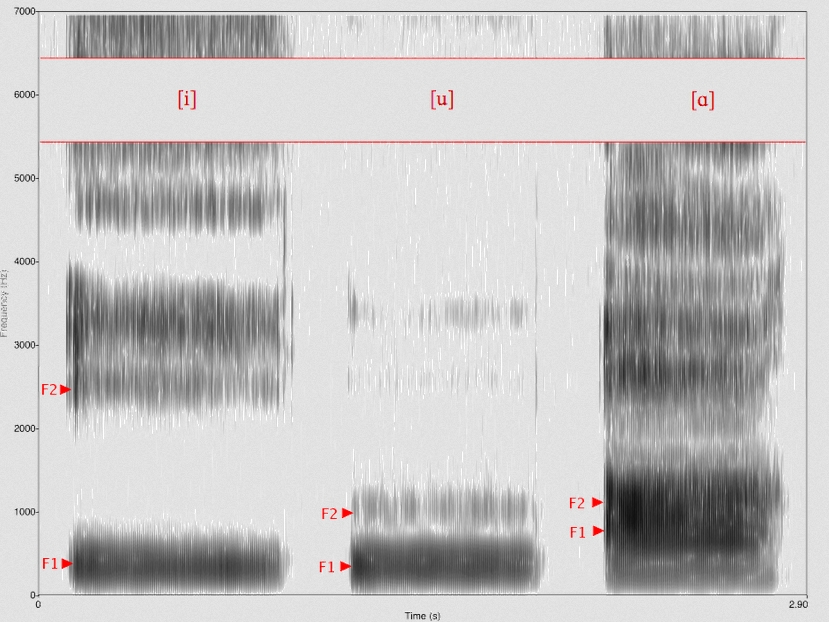
W mowie zwykle daje się wyróżnić kilka częstotliwości rezonansowych, nazywanych formantami. Na widmach akustycznych są one zauważalne jako zagęszczenia tworzące paski. Mnie ten obraz nieco przypomina paski elektroforetyczne na żelu. Formant zwany zerowym mówi o ogólnym tonie dźwięku, podczas gdy rozkład kolejnych formantów odpowiada za barwę dźwięku. Różne głoski (zwłaszcza samogłoski) mają swój charakterystyczny układ formantów, zwłaszcza pierwszego i drugiego, podczas gdy kolejne są zwykle coraz bardziej podobne dla różnych głosek.
Gdyby przewód głosowy był po prostu rurą o stałej średnicy i rozmiarach takich, jak u przeciętnego mężczyzny, o 17,5 cm długości, kolejne formanty miałyby częstotliwości blisko 500 (co odpowiada 1/4 długości fali stojącej tworzącej się w takiej rurze), 1500, 2500 i 3500 Hz. Ale nie jest. Powietrze w przewodzie głosowym obija się o różne struktury z językiem na czele. Gdy język czubkiem dotyka dziąseł (górnych), może powstać syczące [s] lub [z], gdy się nieco uniesie, dotykając twardego podniebienia, syk ten przechodzi w szmer [sz] lub [ż], a dalej w [ś] lub [ź]. Gdy w tym czasie przewód głosowy rozszerzy się o jamę nosową (przez opuszczenie miękkiego podniebienia), powstają głoski nosowe, jak [n] czy [ń].
Z kolei brzmienie samogłosek właściwie nie zależy od języka, a od rozwarcia ust i żuchwy (znaczenie może mieć też układ warg). Od tego zależy częstotliwość formantów. Dwa pierwsze formanty angielskiej samogłoski [a] czy [o] są dość sobie bliskie (różnica 300-400 Hz), a samogłoski [i] dość odległe (ponad 2000 Hz). Nie podaję konkretnych liczb bezwzględnych, bo wbrew pozorom jest dość duży rozrzut. A może właśnie nie wbrew pozorom – ludzkie głosy różnią się między sobą.
Jak napisałem wyżej, za rozróżnianie samogłosek odpowiadają głównie formanty F1 i F2. Formant trzeci w większości przypadków niezbyt odbiega od 2500 Hz u mężczyzn i 3000 Hz u kobiet. Natomiast Johan Sundberg odkrył, że śpiewacy operowi mają zauważalny jeszcze czwarty formant. Badając ich rentgenologicznie, stwierdził, że uzyskują go, obniżając krtań. Ten dodatkowy formant akurat wybija się ponad częstotliwości generowane przez orkiestrę, dzięki czemu śpiewak może ją przekrzyczeć, nie śpiewając wcale głośniej, tj. z większym wysiłkiem. Skutkiem ubocznym jest obniżenie pozostałych formantów, co – jak już wiadomo z tego, co pisałem – skutkuje zniekształceniem samogłosek, np. [i] zaczyna przypominać raczej [ü].
Domowe śpiewanie kolęd raczej nie będzie miało takiego efektu. W ogóle w śpiewaniu popularnym, także profesjonalnym, raczej nie stosuje się takich technik – od wyeksponowania głosu ponad instrumenty jest sprzęt nagłaśniający. Wielu słuchaczy muzyki rockowej czy popowej mniej ceni wirtuozerię, a bardziej autentyzm przekazu, więc piosenkarz, chcąc trafić do takiego odbiorcy, raczej nie będzie zbytnio modyfikował głosu.
Dlaczego przywołuję artykuł Sundberga sprzed 40 lat? Otóż niedawno opublikowano wyniki rentgenologicznego badania śpiewających ptaków. Ptaki mają zupełnie inaczej zbudowaną krtań. W szczególności, co jest dość makabryczne, mogą wydawać głos po odcięciu głowy. Ich analog krtani, tzw. krtań dolna, jest położony dużo bliżej płuc. Ptasia szyja jest zwykle relatywnie długa. Ptasi przewód głosowy nazywany dudami jest również długi, a ponieważ krtań dolna leży bardziej w głębi ciała, dotąd tak naprawdę nie znano mechanizmu wydawania głosu przez ptaki.
Najnowsze badania wskazują, że mimo różnic anatomicznych między ptakami a ludźmi biofizyczny mechanizm jest w zasadzie taki sam. Zatem można powiedzieć, że ptaki śpiewają ludzkim głosem nie tylko w wigilię.
Piotr Panek
ryc. Ish ishwar (z wykorzystaniem oprogramowania Praat), licencja CC-BY 2.0
![]()
Sundberg, J. (1977). The Acoustics of the Singing Voice Scientific American, 236 (3), 82-91 DOI: 10.1038/scientificamerican0377-82
Elemans CP, Rasmussen JH, Herbst CT, Düring DN, Zollinger SA, Brumm H, Srivastava K, Svane N, Ding M, Larsen ON, Sober SJ, & Švec JG (2015). Universal mechanisms of sound production and control in birds and mammals. Nature communications, 6 PMID: 26612008
Komentarze
PS. Akustyków czy mechaników falowych czytających, jak nonszalancko synonimizuję częstotliwości, długości itd., uprasza się o pobłażliwość.
Czy rzeczywiscie koled nie mozna juz spiewac bez zazenowania? O co chodzi – o muzyke czy slowa? W mojej skromnej opinii koledy sa naszym pieknym dziedzictwem muzycznym, a ich slowa – coz, dziecinne, naiwne i czesto urocze. Moze i dobrze, ze odchodzi sie od ich spiewania, uszy bolaly od tych wszystkich manieryzmow, jakim je poddawano. Na szczescie mozna ich jeszcze sluchac w szlachetnym wykonaniu. Robie to zawsze z ogromna przyjemnoscia.
Gospodarz bloga chyba tez zywi w glebi duszy jakies cieple uczucia do naszego folkloru, skoro mowi, ze ptaki spiewaja ludzkim glosem nie tylko w noc wigilijna. Ile w tym odniesienia do wspolnej swiadomosci i jak to ladnie brzmi na zakonczenie wywodow naukowych!
@Kruk
To nie tak. Kolęd nie śpiewa się nie ze względu na zażenowanie tylko strach przed odpowiedzialnością. Niejaki Nowak z Krakowa tylko czeka z gotową do użytku obrazą jego uczuć religijnych. Nie wiem, czy mieszka Pan w Polsce, ale cechą charakterystyczną tegorocznego okresu przed świętami jest CISZA i ciemnota (=brak ozdób). I brak atmosfery przedświątecznej. Ludzie się boją. Gdzieś tu był artykuł, że sklepy czy firmy reklamowe dostały po nosie (od sądów Nowaka) i siedzą cicho. Prawdopodobnie niedługo wyjdzie podręcznik instrukcja, w jakich okolicznościach co wolno śpiewać. Najgorzej jest chyba z tymi niemieckimi kolędami (a to wszystkie ważniejsze) bo za ich śpiewanie grozi ponadto oskarżenie o zdradę.
Dlatego radzę Panu niech Pan zdziera swoje fałdy głosowe bezgłośnie albo przeniesie się do jakiegoś kraju mniej chrześcijańskiego. Bo tutaj prawdziwi chrześcijanie zbierają już kamienie do rzucania w takich jak Pan. Daesh wzorem.
P.S. Śpiewanie hymnu na 1 Maja też będzie zakazane. Radzę śpiewać na zapas.
Tak naprawdę wtręt o kolędach był zagajeniem do obecnego okresu. Natomiast kolędy kolędami, ludzie, przynajmniej z mojego kręgu kulturowego, śpiewają mniej chętnie niż nasi przodkowie. Nie znaczy to, że w ogóle muzyka przestała mieć znaczenie, ale tak, jak wiele mniej ludzie robią teraz własnoręcznie, tak i mniej śpiewają. Skoro mniej śpiewają, mniej są w tym wyrobieni. Skoro mniej wokół innych śpiewających tak sobie, to bardziej może wzbudzać wstyd własna niedoskonałość. I tak się napędza.
Śpiewanie jako takie jest bardzo głęboko zakorzenione w kulturze, także w tej odległej archeologicznie, czy wręcz paleontologicznie. Właściwie nie ma kultury, w której nie byłoby jakiejś formy muzyki, a własny głos jest podstawowym instrumentem i właściwie każdy człowiek jakoś muzykę rozpoznaje (choć pisaliśmy tu już a amuzji). To tak, jak z językiem. Niektórzy nawet zachęceni chomskistowską ideą uniwersaliów językowych szukają uniwersaliów muzycznych – z podobnie umiarkowanym skutkiem. Dunbar stawia hipotezę, że wspólne muzykowanie (śpiew, taniec itp.) było jednym z etapów tworzenia wspólnot w miarę rozrastania się podstawowych jednostek populacyjnych – kiedy nie tylko iskanie, ale nawet plotkowanie o wspólnych znajomych nie dawało już rady objąć wszystkich pobratymców, ale jeszcze zanim społeczności rozrosły się do rozmiarów, które spajać może coś jeszcze bardziej ogólnego, jak religia czy ideologia.
Ale to może na inny wpis.
@Panek
Mój wpis odnosił się do czego innego. Natomiast co do muzykowania jako takiego, to jest chyba nawet lepiej niż Pan mówi. Jest wręcz coraz lepiej. Powstaje mnóstwo grup i zespołów. coraz więcej (procentowo) ludzi gra na własnych instrumentach. Widział Pan festiwal amatorskich grup muzycznych? Co ciekawe, coraz więcej mamy też muzyki w tonacji średniowiecznej. Był Pan kiedyś na takim średniowiecznym święcie, do którego przygotowuje się całe miasto przez cały rok. Wszyscy mieszkańcy. To jest przeżycie.
Ale niestety nie w Polsce. Tutaj z jednej strony muzyka ludowa została całkowicie zniszczona przez zespoły Mazowsze i Śląsk. Odebrana ludziom dla władzy. I trwa to do dzisiaj bo muzyka tutaj nie jest po to, żeby ludziom sprawiała przyjemność tylko to jest dobro narodowe, które trzeba przed ludźmi chronić. Niedawno TV pokazała występ Mazowsza. To była prezentacja dumy narodowej, nie muzyka.
Istnieje wiele zespołów i widziałem kiedyś festiwale ale to zawodowcy, którzy przynoszą kulturę „ciemnym masom” i oczywiście najpierw pobierają opłaty. Odpychające. Czy to się ostatnio zmienia, niech pisze ktoś inny. Ale ktoś, kto szanuje ludzi a nie jest „elitą” od uświadamiania motłochu. Jak komentarze na blogach Polityki.
Natomiast kolędy jak i całe święta Bożenarodzeniowe proponuję zostawić dzieciom. To dla nich wielkie przeżycie. Kolendy są dla nich i to tak bardzo, że nawet Turcy w Niemczech te święta obchodzą właśnie z dziećmi. Niedobrze, że to piękne przeżycie zamienia się w religijny terror.
P.S. Disco Polo miało (ma) szansę rozrosnąć się do wspaniałej muzyki ludowej. Ale przy takim nastawieniu „elity”.
@ZWO
wielu to już w przeszłości przewidywało, że śpiewać tego co polskie nie będziemy (odniesienie do wspomnianego hymnu, a nie kolęd), a jakoś wciąż śpiewamy. teraz to nawet jeszcze niedawno zdeklarowani antypolscy Polacy owijają się w polską flagę jakoś nie czując wstydu i zażenowania.
@panek
tekst fajny a najciekawsze na koncu. co z tymi ptakami i wydaniem przez nich głosu po ścieciu głowy, dlaczego go wydają?
A ja se pośpiewam
@eRK
Pewnie chodzi o odruchowe krzyki. To nie jest tak, że zdekapitowany skowronek nagle zaczyna trele. Tyle, że o ile ssak z przeciętą szyją jest już tylko w stanie rzęzić, o tyle ptak jeszcze może (nawet jeśli zwykle tego nie robi) wydać dźwięk bardziej przypominający normalny głos.
A czy zbadał już ktoś, czy odcięta ptasia głowa słyszy jeszcze ostatni krzyk szyi?
Te fałdy głosowe to czynnik selekcji czy fanaberia natury? Czy orangutany mają te fałdy głosowe? Kiedy się one pojawiły?
Fałdy jako takie służą u ssaków zamykaniu dróg oddechowych. U orangutanów są również i również służą wydawaniu dźwięków. Zasadnicza różnica, która sprawia, że ludzie wydają dźwięki, które nazywamy artykułowanymi to obniżenie pozycji krtani. Sprawia to, że rezonatorem jest nie tylko jama gębowa (ustna), ale też gardło. Z drugiej strony, ludzie nie mają dodatkowych worków rezonansowych typowych dla większości naczelnych.
Ważna jest też koordynacja oddechowa, która umożliwia tworzenie dłuższych wypowiedzi o bardziej skomplikowanej niż ryk/wycie strukturze, do której unerwienie też wydaje się u ludzi specyficzne (w porównaniu z innymi małpami).
@panek
Byłam wczoraj na koncercie w FN. Tylko trudności, które zaniedbanym polskim głosom stawiały opracowania wybrane przez nieocenionego Henryka Wojnarowskiego, powstrzymywały podśpiewywanie publiczności (no, dobrze, nie wtóruje się solistce). Kiedy w finale dyrygent zaprosił publiczość do „Wśród nocnej ciszy” śpiewali wszyscy, i zażenowany mógł być tylko ten, kto nie śpiewał. Dzień wcześniej na koncercie chóru chłopięcego polskie kolędy śpiewali z małymi i większymi śpiewakami nie tylko byli chórzyści, ale też publiczność, która w szatni podchwyciła też łacińskie „Gaudete, Christus est natus” (kto nie zna niech posłucha https://www.youtube.com/watch?v=2KSxg9Ij5r8). Oj, panowie, zamiast narzekać, posłuchajcie kiedyś śląskich kolęd u św. Trójcy na Placu Małachowskiego. Tylko weźcie po dodatkowym swetrze, bo choć duszy gorąco, ciało marznie.